
Avvertenze
Relativamente agli aspetti di sicurezza, poiché i progetti sono basati su alimentazione elettrica in bassissima tensione erogata dalla porta usb del pc o da batterie di supporto o alimentatori con al massimo 9V in uscita, non ci sono particolari rischi di natura elettrica. È comunque doveroso precisare che eventuali cortocircuiti causati in fase di esercitazione potrebbero produrre danni al pc, agli arredi ed in casi estremi anche a ustioni, per tale ragione ogni qual volta si assembla un circuito, o si fanno modifiche su di esso, occorrerà farlo in assenza di alimentazione e al termine dell’esercitazione occorrerà provvedere alla disalimentazione del circuito rimuovendo sia il cavo usb di collegamento al pc che eventuali batterie dai preposti vani o connettori di alimentazione esterna. Inoltre, sempre per ragioni di sicurezza, è fortemente consigliato eseguire i progetti su tappeti isolanti e resistenti al calore acquistabili in un qualsiasi negozio di elettronica o anche sui siti web specializzati.
Al termine delle esercitazioni è opportuno lavarsi le mani, in quanto i componenti elettronici potrebbero avere residui di lavorazione che potrebbero arrecare danno se ingeriti o se a contatto con occhi, bocca, pelle, etc. Sebbene i singoli progetti siano stati testati e sicuri, chi decide di seguire quanto riportato nel presente documento, si assume la piena responsabilità di quanto potrebbe accadere nell’esecuzione delle esercitazioni previste nello stesso. Per i ragazzi più giovani e/o alle prime esperienze nel campo dell’Elettronica, si consiglia di eseguire le esercitazioni con l’aiuto ed in presenza di un adulto.
Note sul Copyright
Tutti i marchi riportati appartengono ai legittimi proprietari; marchi di terzi, nomi di prodotti, nomi commerciali, nomi corporativi e società citati possono essere marchi di proprietà dei rispettivi titolari o marchi registrati d’altre società e sono stati utilizzati a puro scopo esplicativo ed a beneficio del possessore, senza alcun fine di violazione dei diritti di Copyright vigenti. Quanto riportato in questo documento è di proprietà di Roberto Francavilla, ad esso sono applicabili le leggi italiane ed europee in materia di diritto d’autore – eventuali testi prelevati da altre fonti sono anch’essi protetti dai Diritti di Autore e di proprietà dei rispettivi Proprietari. Tutte le informazioni ed i contenuti (testi, grafica ed immagini, etc.) riportate sono, al meglio della mia conoscenza, di pubblico dominio. Se, involontariamente, è stato pubblicato materiale soggetto a copyright o in violazione alla legge si prega di comunicarlo tramite email a info@bemaker.org e provvederò tempestivamente a rimuoverlo.
Roberto Francavilla
Intelligenza Artificiale e il Machine Learning
Nella prima lezione abbiamo solo citato la definizione di “Intelligenza Artificiale” adesso vorrei spingermi oltre e cercare di spiegarvi, a modo mio e nella maniera più semplice possibile, in che cosa consiste l’implementazione di una intelligenza artificiale in una macchina. Ovviamente sono consapevole che trattasi di un argomento che richiede basi teoriche di livello universitario, per cui, ai più esperti, consentitemi le semplificazioni che farò per cercare di rendere l’argomento comprensibile anche per i più giovani e per coloro che desiderano affacciarsi a questo meraviglioso mondo.
Fino al ventennio scorso si intendeva per Intelligenza Artificiale la creazione di un enorme database con tutti i comportamenti che un computer doveva avere. Ad ogni comportamento vi erano associate delle condizioni che dovevano verificarsi. Ad esempio: se fuori c’è il sole il computer deve sorridere, etc.. quindi il computer non faceva altro che verificare le varie condizioni ed in funzione di esse determinava il comportamento da tenere… questi enormi database “comportamentali” venivano chiamati “Sistemi Esperti” (che io ricordi, la IBM fu una delle prime ad implementare uno di questi sistemi esperti… il famoso Deep Blue che batté a scacchi il noto campione Kasparov grazie alla memorizzazione di milioni di combinazioni di mosse derivanti da esperienze di altre partite giocate realmente e precedentemente memorizzate).

Con il tempo si videro i limiti di questo modo di programmare le macchine affinché potessero stabilire un determinato comportamento…. Primo fra tutti, limiti di tipo hardware… gli enormi spazi di memoria per contenere tutte le possibili combinazioni comportamentali da prevedere ed anche la necessità di avere disponibili “più computer” che lavorassero in parallelo per la potenza di calcolo necessaria all’elaborazione dei confronti di tutte le condizioni per le operazioni decisionali. Ma con l’avvento delle Reti Neurali le cose cambiarono… infatti, grazie ad esse, sono nati nuovi algoritmi di analisi e quindi si è passati dai Sistemi Esperti al “Machine Learning” e con questo c’è la svolta!
Un esempio di ciò è il famoso computer Alpha Zero che a differenza di Deep Blue non ha ricevuto alcuna prememorizzazione di partite giocate, ma ha in pratica imparato a giocare a scacchi da solo, effettuando milioni di partite contro se stesso e conoscendo solo le regole del gioco degli scacchi.

Già da quanto anticipato, capite comunque che avremo a che fare con una metodologia di programmazione diversa da quella usuale.
Infatti un programma per un computer (anche chiamato software) realizzato con il metodo classico si basa nel definire gli algoritmi di elaborazione da parte del programmatore e trasformarli in codice di programma, dopodiché il computer. in base agli input che gli vengono inseriti. definirà dei corrispondenti output sulla base degli algoritmi implementati.
Nel Machine Learning il programma in realtà si autogenera ed è la macchina stessa che lo realizza, infatti funziona così: il programmatore stabilisce un modello, al modello viene insegnato a capire qual è l’output corretto rispetto a quello non corretto (indicandone anche l’errore di scostamento rispetto all’output corretto), dopodiché la macchina continua ad imparare da sola riducendo sempre di più l’errore che commette rispetto all’output atteso.
Sperando di non avervi mandato in tilt nulla… ho bisogno di ancora della vostra attenzione, per cui facciamo un ultimo sforzo di concentrazione.
Andiamo a vedere con maggior dettaglio quanto spiegato poc’anzi introducendo anche dei termini nuovi utilizzati nel mondo del Machine Learning.
Prima di tutto desidero spiegarvi che quanto verrà trattato nelle prossime pagine è applicabile ai cosiddetti microcontrollori, questo farà si che non necessiteremo di calcolatori superpotenti, ma sarà sufficiente il nostro Microcontrollore Arduino Nano 33 BLE Sense, il nostro PC ed un semplice collegamento alla rete Internet. Per questo motivo questa scienza non si chiama Machine Learning, ma bensì “Tiny Machine Learning” (in forma abbreviata “tinyML” – tiny sta per “minuscolo”).
La cosa che mi preme farvi capire è che stiamo parlando di una tecnologia giovane, sebbene di Machine Learning se ne parli da anni, ma il suo campo di applicazione, fino a pochi anni fa, era relegata a computer con elevata potenza di calcolo. Il TinyML invece riguarda tutte quelle applicazioni di piccole dimensioni (addirittura per i cosiddetti, dispositivi indossabili).
Infatti la regola per classificare cosa è “Tiny” è quella dell’ “1”, cioè dispositivi che hanno processori che costano circa 1 $ , che hanno al massimo 1 Mb di RAM, che hanno una velocità massima di clock di 1 Ghz, che la rete neurale abbia un consumo massimo di circa 1 mW e che devono poter essere alimentati da batterie a bottone con durata di almeno 1 anno.
Si stima che nel prossimo futuro il tinyML occuperà una fetta di mercato significativa ed i settori più recettivi saranno: l’industria per la realizzazione di veicoli in genere (auto, treni, aerei, etc..), l’automazione industriale e quella degli elettrodomestici con inclusa la domotica. Non ce ne stiamo ancora accorgendo, ma una piccola rivoluzione è già in atto…
Creazione di una Intelligenza Artificiale con il Deep Learning
Il processo di creazione di una Intelligenza Artificiale è costituito da fasi ben precise:
Fase 1 – scelta del Modello di “rete neurale” (ovvero, semplificando, scelta dell’Algoritmo di apprendimento) che consentirà al Microcontrollore di creare un database di esperienze derivanti dall’addestramento, in funzione dell’obiettivo da raggiungere.
Fase 2 – creazione del database di esperienze, questa fase è chiamata “addestramento” e si distingue in due momenti, uno iniziale dove il database iniziale è praticamente realizzato “a tavolino” dal programmatore. In questo database vengono introdotti i concetti di “risultato corretto” e “risultato non corretto”. Il secondo momento è l’arricchimento del database di esperienze (con risultati corretti e non corretti) durante la fase di auto-apprendimento. Ovvero al modello vengono forniti gli input e poi il risultato viene validato con anche l’indicazione dello scostamento (accuratezza) dell’output rispetto a quello atteso.
Fase 3 – al termine dell’addestramento c’è l’implementazione del “modello addestrato” in funzione del microcontrollore scelto. In questa fase si ottimizza e si ridimensiona il codice del programma opportunamente in funzione delle capacità di memoria del microcontrollore.
Fase 4 – caricamento del modello addestrato sul microcontrollore che nel nostro caso è Arduino Nano per generare l’”inferenza”. cioè il processo decisionale che porta all’output conseguente a degli input sulla base di ciò che il modello addestrato ha elaborato. Quindi l’inferenza può essere definita come quel processo di un ragionamento costruito sulla base dell’apprendimento.
Una volta caricato il programma di ML sul microcontrollore, esso è pronto a svolgere la sua attività e darà un output in funzione degli input che gli verranno inviati.
Le fasi sopra descritte sono una sintesi di diverse sotto attività che per semplicità non ho riportato, ma che comunque vedremo in seguito, ora la cosa su cui desideravo attirare la vostra attenzione è che il processo sopra descritto, quello indicato con le Fasi da 1 a 4, è chiamato “Deep Learning”.
Vediamo di rappresentare graficamente quanto riportato sopra:
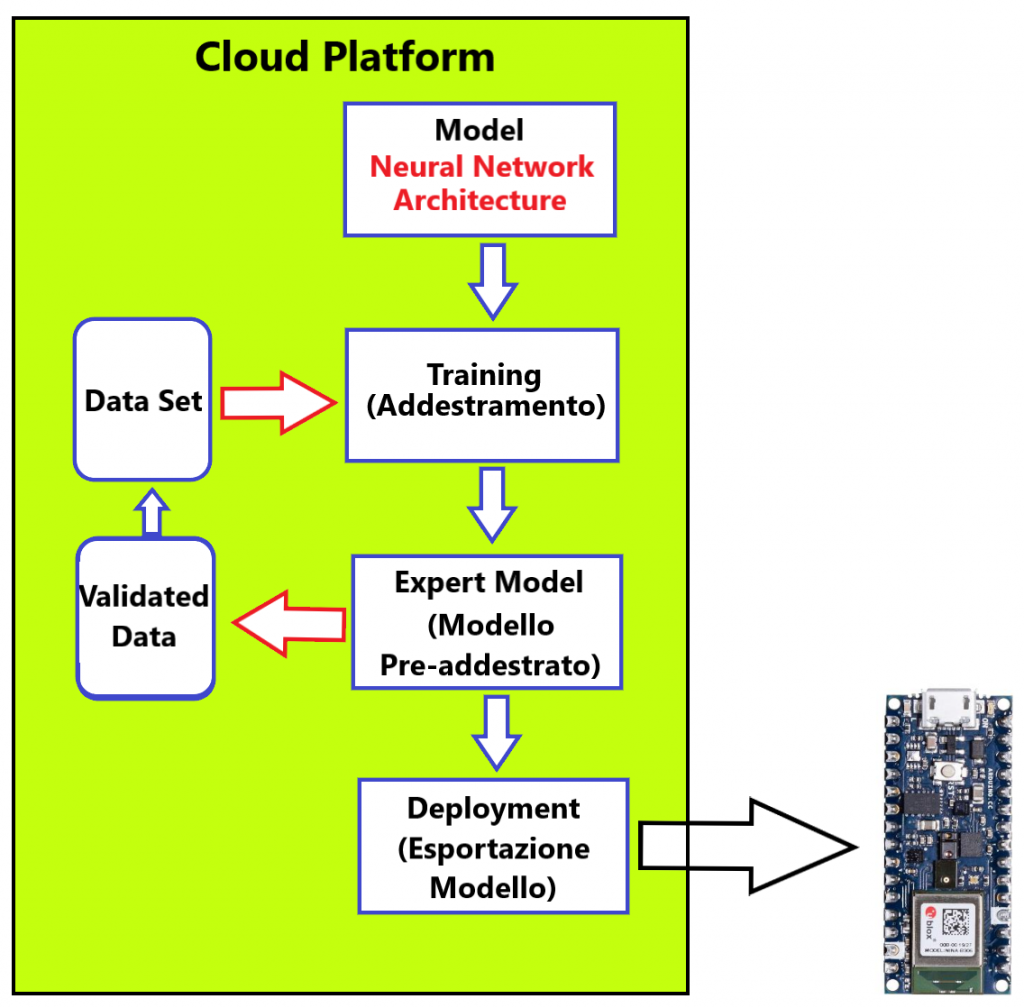
Per quanto riguarda l’intero processo dalla scelta del Modello, sino alla creazione del programma di AI, con il modello pre-addestrato, da caricare sul microcontrollore (cioè il contenuto del box di colore verde chiaro), in Internet esistono diverse piattaforme che ci aiutano a realizzarlo. Quella a cui faremo riferimento, perché è open source, è totalmente gratuita ed il supporto è dato da una vasta comunità è TensorFlow, ma ci sono anche tante altre piattaforme (che personalmente non conosco) disponibili, fra cui Edge Impulse, Neuton, etc.. che mettono a disposizione risorse gratuite di cui comunque vi inserisco alcuni link se desiderate visionarli.



Prima di addentrarci in nuovi capitoli di teoria per imparare a realizzare una Intelligenza Artificiale del tipo TinyML, cerchiamo di familiarizzare con questo nuovo modo di operare. Per fare questo utilizzeremo Modelli già pre-addestrati e disponibili su TensorFlow Lite.
Occorre precisare che TensorFlow Lite è la versione di TensorFlow per applicazioni TinyML ovvero per il Machine Learning applicato ai Microcontrollori.
Istallazione della Libreria TensorFlow Lite
Per poterci tuffare nel mondo del TinyML occorre caricare la Libreria TensorFlow Lite nel nostro ambiente di sviluppo per Arduino. Per fare ciò occorre andare su Strumenti -> Gestione Librerie… e digitare “arduino_tensorflow lite” e cliccare su istalla.
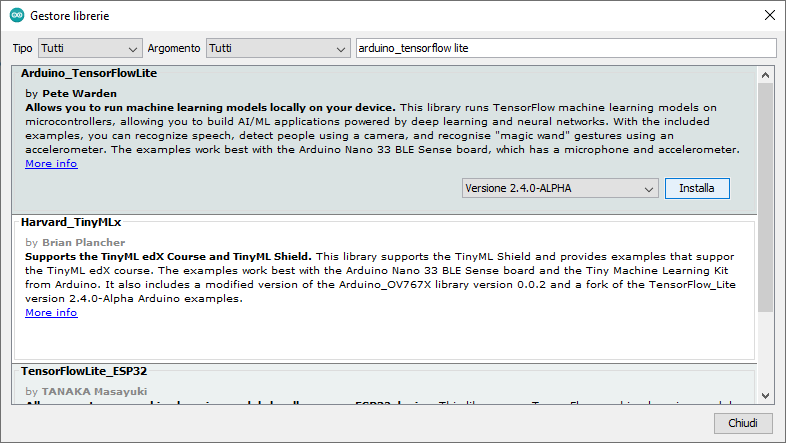
Per tutti i progetti che seguono abbiamo bisogno solo della scheda Nano BLE Sense, di un PC e del cavo USB di collegamento.



PAI-014: Hello World - TinyML
Questo progetto rappresenta l’ingresso nel mondo del TinyML, per questo motivo come in altri ambiti, il primo progetto, quello “più semplice”, è sempre chiamato Hello World.
Ora, per noi, sebbene questo sia il progetto più semplice, aprendo il codice che segue, non ci capiremo molto, ma non fa nulla. L’obiettivo, non è capire come è stato realizzato il codice (perché lo vedremo in seguito), ma è capire cosa sta facendo Arduino Nano.
L’obiettivo del progetto Hello World consiste nel far costruire ad Arduino Nano una funzione già nota per verificare il corretto apprendimento. La funzione che deve imparare a costruire è quella del seno, cioè una funzione che deriva dalla trigonometria.
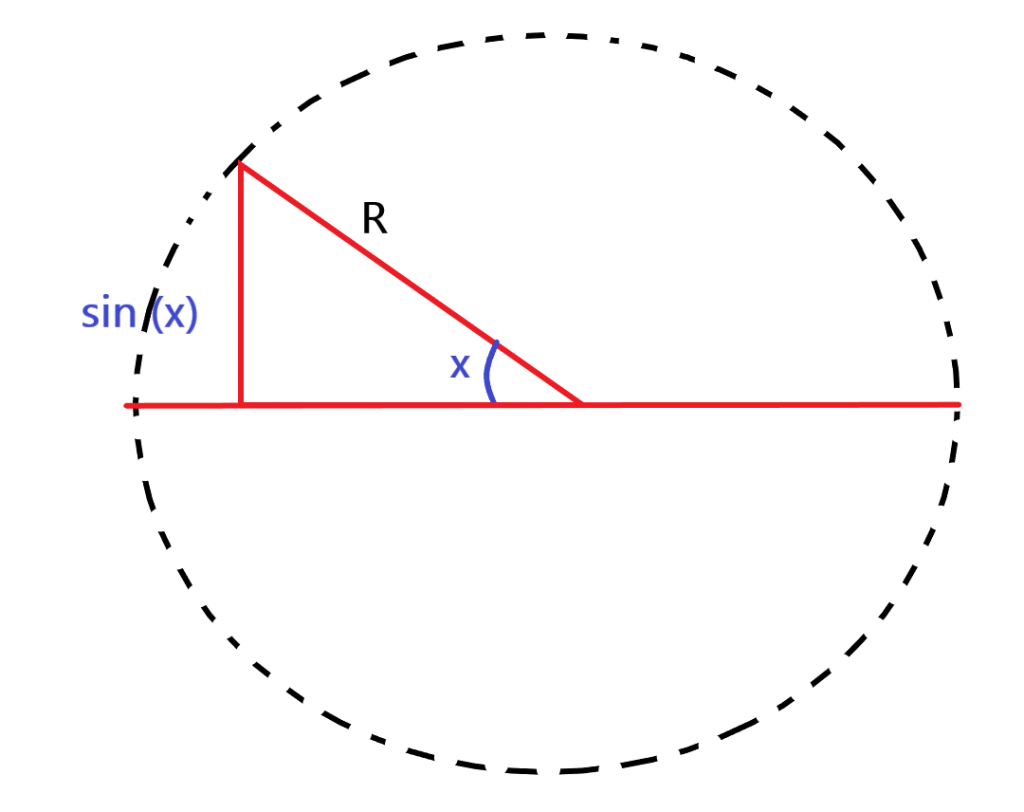
La funzione seno, indicata con sin(x) o con sen(x), è una funzione trigonometrica, periodica e limitata. Questa funzione la si ottiene dalla regola che in un triangolo rettangolo, di ipotenusa 1 (cioè il raggio del cerchio)1, il cateto relativo all’altezza del triangolo rettangolo è il seno dell’angolo compreso fra l’ipotenusa e l’asse delle ascisse (cioè l’angolo opposto). Se ruotassimo l’ipotenusa, si descriverebbe un cerchio di raggio R=1 e l’altezza del triangolo sarebbe sempre il seno dell’angolo opposto. E’ facilmente intuibile che a 0° o meglio a 0 radianti, il seno è pari a 0, a 90°, cioè a PiGreco/2, il seno è uguale al raggio R = 1, poi a 180°, il seno ritorna ad essere 0 e a 270°, cioè a 3/2 di PiGreco, il seno diventa -1. L’andamento della funzione seno è quindi quella riportata in basso.
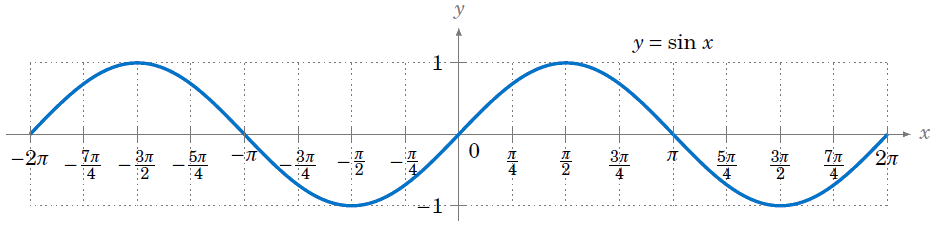
Ora immaginate di dire alla Nano, costruisci il seno dell’angolo x, senza dargli la funzione, ma dare soltanto una serie limitata di coppie di numeri che rappresentano l’ordinata e l’ascissa della funzione e che la Nano stessa dovrà costruirsi la funzione derivante. Ovviamente dovremo anche dirgli quando sta sbagliando e in che termini è l’errore. Beh! Il risultato di tale modello lo potete osservare in questo progetto.
Una volta istallata la libreria, andate su :
File -> Esempi -> Arduino_TensorFlow Lite -> Hello Word
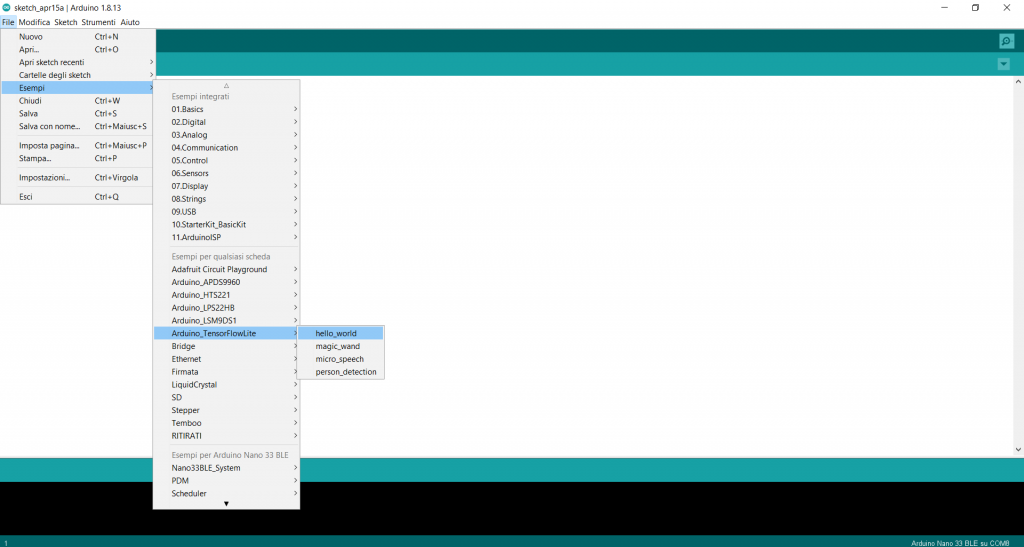
A questo punto procedete come al solito, collegate la Nano via USB al PC e cliccate due volte il tastino per l’upload del programma di esempio.
Una volta caricato sulla Nano il codice e cambiata la porta COM, attivate il Plotter Seriale e vedrete che la Nano disegna una curva molto vicina alla funzione seno, di seguito due screenshot:
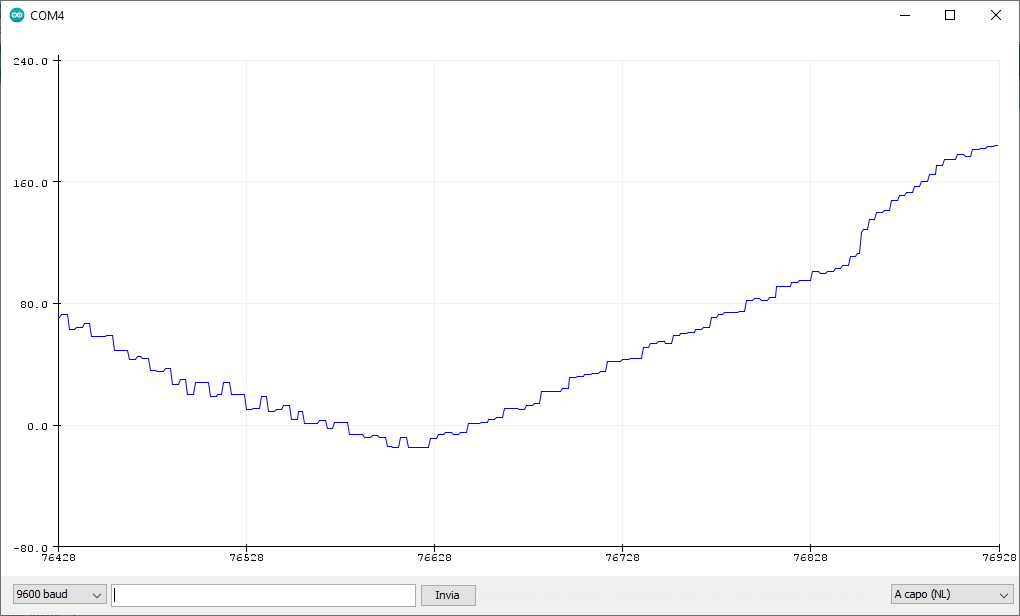
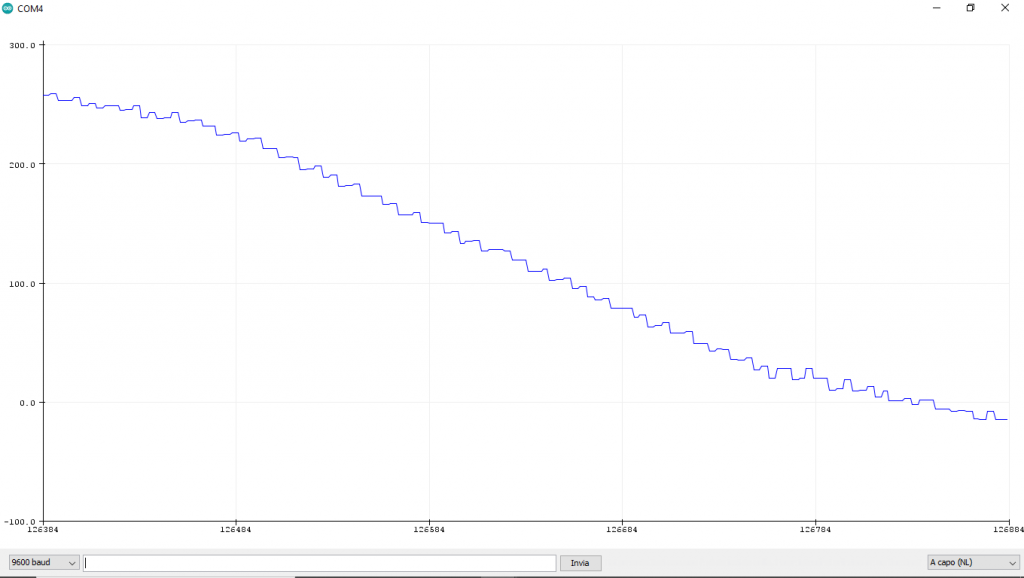
Desidero farvi osservare come la curva presenti delle “dentature”, il motivo è che il modello effettua ovviamente delle approssimazioni e quindi è comunque presente un errore, l’errore sarà tanto più piccolo, quanto migliore sarà il modello addestrato.
Ovviamente, il rovescio della medaglia è che un modello meglio addestrato significa un codice pesante in termini di richiesta di memoria, ciò che il microcontrollore non ha e pertanto occorre sempre il giusto compromesso.
Se hai trovato la lezione interessante fai una donazione mi aiuterai a realizzarne tante altre.
