
Avvertenze
Relativamente agli aspetti di sicurezza, poiché i progetti sono basati su alimentazione elettrica in bassissima tensione erogata dalla porta usb del pc o da batterie di supporto o alimentatori con al massimo 9V in uscita, non ci sono particolari rischi di natura elettrica. È comunque doveroso precisare che eventuali cortocircuiti causati in fase di esercitazione potrebbero produrre danni al pc, agli arredi ed in casi estremi anche a ustioni, per tale ragione ogni qual volta si assembla un circuito, o si fanno modifiche su di esso, occorrerà farlo in assenza di alimentazione e al termine dell’esercitazione occorrerà provvedere alla disalimentazione del circuito rimuovendo sia il cavo usb di collegamento al pc che eventuali batterie dai preposti vani o connettori di alimentazione esterna. Inoltre, sempre per ragioni di sicurezza, è fortemente consigliato eseguire i progetti su tappeti isolanti e resistenti al calore acquistabili in un qualsiasi negozio di elettronica o anche sui siti web specializzati.
Al termine delle esercitazioni è opportuno lavarsi le mani, in quanto i componenti elettronici potrebbero avere residui di lavorazione che potrebbero arrecare danno se ingeriti o se a contatto con occhi, bocca, pelle, etc. Sebbene i singoli progetti siano stati testati e sicuri, chi decide di seguire quanto riportato nel presente documento, si assume la piena responsabilità di quanto potrebbe accadere nell’esecuzione delle esercitazioni previste nello stesso. Per i ragazzi più giovani e/o alle prime esperienze nel campo dell’Elettronica, si consiglia di eseguire le esercitazioni con l’aiuto ed in presenza di un adulto.
Note sul Copyright
Tutti i marchi riportati appartengono ai legittimi proprietari; marchi di terzi, nomi di prodotti, nomi commerciali, nomi corporativi e società citati possono essere marchi di proprietà dei rispettivi titolari o marchi registrati d’altre società e sono stati utilizzati a puro scopo esplicativo ed a beneficio del possessore, senza alcun fine di violazione dei diritti di Copyright vigenti. Quanto riportato in questo documento è di proprietà di Roberto Francavilla, ad esso sono applicabili le leggi italiane ed europee in materia di diritto d’autore – eventuali testi prelevati da altre fonti sono anch’essi protetti dai Diritti di Autore e di proprietà dei rispettivi Proprietari. Tutte le informazioni ed i contenuti (testi, grafica ed immagini, etc.) riportate sono, al meglio della mia conoscenza, di pubblico dominio. Se, involontariamente, è stato pubblicato materiale soggetto a copyright o in violazione alla legge si prega di comunicarlo tramite email a info@bemaker.org e provvederò tempestivamente a rimuoverlo.
Roberto Francavilla
Impacchettamento del Modello Hello World per realizzare uno Sketch

Dopo aver realizzato ed ottimizzato il nostro modello che riesce a prevedere i valori di una funzione sin(x), si passa alla fase di “impacchettamento” per realizzare lo sketch.
Questa, purtroppo, è la fase più lunga e noiosa, anche perché sarebbe troppo complicato spiegarla nei dettagli, specialmente se non si hanno robuste basi di informatica. Per questo motivo vi darò, per questa fase, solo indicazioni procedurali lavorando sul nostro modello.
È ovvio che poi la procedura di impacchettamento è facilmente generalizzabile e quindi può essere applicata a qualsiasi altro modello di Machine Learning.
Ridimensionamento o Quantizzazione del Modello
Per poter utilizzare il modello di Machine Learning sui microcontrollori, occorre renderlo “tiny” e
già si intuisce che il nostro modello necessiterà di trasformazioni. La prima è quella di “ridimensionamento”, cioè ridurre il più possibile la quantità di memoria impegnata per l’esecuzione del modello.
Per fare questo ritorniamo al file su Colab di Google che avevamo precedentemente nominato “Seno_Function_2.ipynb” e salviamolo con il nome “Seno_Function_3.ipynb”.
Andiamo all’ultima cella ed aggiungiamo una cella di codice e scriviamo il seguente codice:
# Convert the model to the TensorFlow Lite format without quantization
converter = tf.lite.TFLiteConverter.from_keras_model(model_2)
tflite_model = converter.convert()
# Save the model to disk
open(“sine_model.tflite”, “wb”).write(tflite_model)
# Convert the model to the TensorFlow Lite format with quantization
converter = tf.lite.TFLiteConverter.from_keras_model(model_2)
# Indicate that we want to perform the default optimizations,
# which includes quantization
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# Define a generator function that provides our test data’s x values
# as a representative dataset, and tell the converter to use it
def representative_dataset_generator():
for value in x_test:
# Each scalar value must be inside of a 2D array that is wrapped in a list
yield [np.array(value, dtype=np.float32, ndmin=2)]
converter.representative_dataset = representative_dataset_generator
# Convert the model
tflite_model = converter.convert()
# Save the model to disk
open(“sine_model_quantized.tflite”, “wb”).write(tflite_model)
Praticamente con questo codice aggiunto effettuiamo due trasformazioni, la prima rendiamo il modello leggibile da TensorFlow Lite e salviamo la trasformazione in un file che si chiama “sine_model.tflite”, la seconda invece effettua una ottimizzazione di memoria utilizzata (chiamata “quantizzazione”).
Una delle ottimizzazioni automatiche (di default) che vengono effettuate con il comando:
converter.optimizations = [tf.lite.Optimize.DEFAULT]
è quella di trasformare la gestione dei numeri, da numeri a virgola mobile (che richiedono 32 bit di memoria) a numeri interi (che richiedono solo 8 bit di memoria). E’ ovvio che con questa trasformazione si perderà in precisione, ma comunque è una perdita di precisione nel valore previsto considerata accettabile (visto anche che il modello comunque non dà un valore esatto!). Quanto detto vale in generale, perché bisogna fare attenzione con questa ottimizzazione, infatti quando il risultato atteso è un numero molto piccolo (nel nostro caso ricordiamoci che va da 0 a +/- 1) passare da un numero decimale ad intero si potrebbero perdere cifre significative e quindi falsare il risultato, ma di questo ne parliamo anche in seguito. Adesso concentriamoci sulla procedura di impacchettamento.
A questo punto andiamo su Runtime e clicchiamo su Riavvia ed esegui tutto..
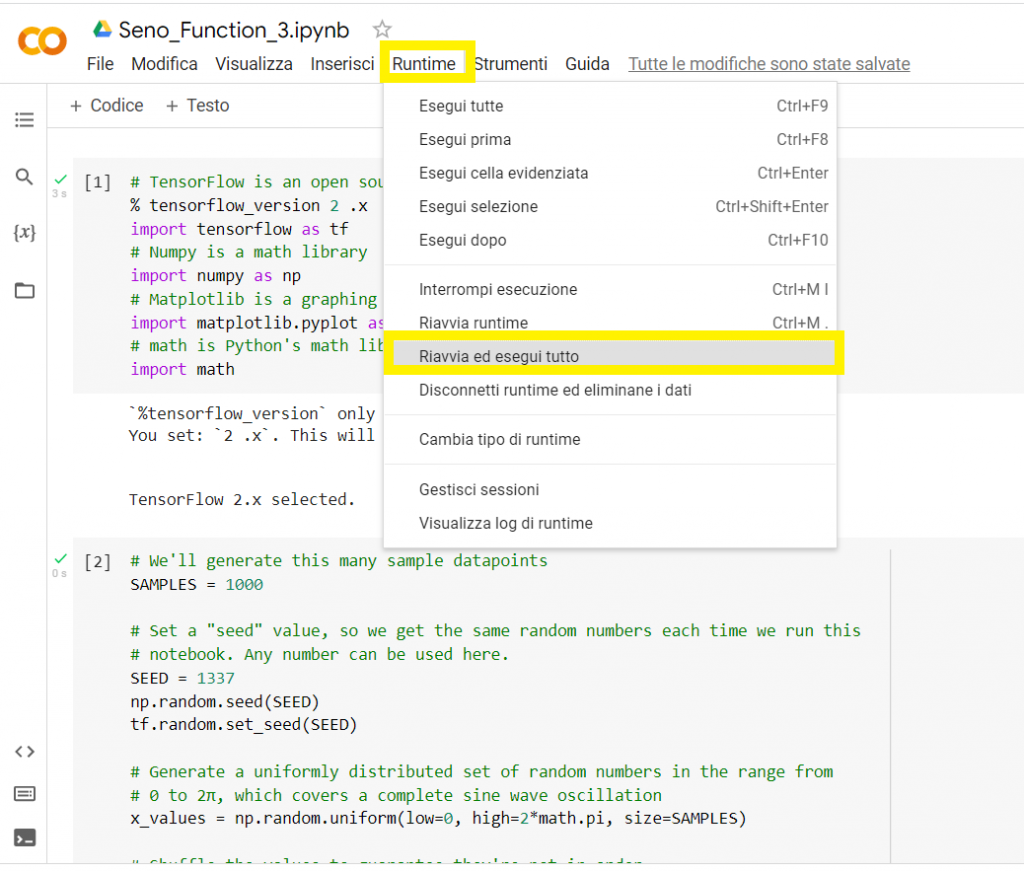
A questo punto abbiamo due files, il modello modificato per TFLite e il modello, sempre per TF Lite, ma ridotto o quantizzato.
Verifichiamo che i due nuovi modelli conservano le caratteristiche previsionali del modello di partenza. Per fare questo occorre lavorare con TFLite. Per cui aggiungiamo ancora una cella di codice su Colab e scriviamo il seguente codice:
# Instantiate an interpreter for each model
sine_model = tf.lite.Interpreter(‘sine_model.tflite’)
sine_model_quantized = tf.lite.Interpreter(‘sine_model_quantized.tflite’)
# Allocate memory for each model
sine_model.allocate_tensors()
sine_model_quantized.allocate_tensors()
# Get indexes of the input and output tensors
sine_model_input_index = sine_model.get_input_details()[0][“index”]
sine_model_output_index = sine_model.get_output_details()[0][“index”]
sine_model_quantized_input_index = sine_model_quantized.get_input_details()[0][“index”]
sine_model_quantized_output_index = sine_model_quantized.get_output_details()[0][“index”]
# Create arrays to store the results
sine_model_predictions = []
sine_model_quantized_predictions = []
# Run each model’s interpreter for each value and store the results in arrays
for x_value in x_test:
# Create a 2D tensor wrapping the current x value
x_value_tensor = tf.convert_to_tensor([[x_value]], dtype=np.float32)
# Write the value to the input tensor
sine_model.set_tensor(sine_model_input_index, x_value_tensor)
# Run inference
sine_model.invoke()
# Read the prediction from the output tensor
sine_model_predictions.append(
sine_model.get_tensor(sine_model_output_index)[0])
# Do the same for the quantized model
sine_model_quantized.set_tensor(sine_model_quantized_input_index, x_value_tensor)
sine_model_quantized.invoke()
sine_model_quantized_predictions.append(
sine_model_quantized.get_tensor(sine_model_quantized_output_index)[0])
# See how they line up with the data
plt.clf()
plt.title(‘Comparison of various models against actual values’)
plt.plot(x_test, y_test, ‘bo’, label=’Actual’)
plt.plot(x_test, predictions, ‘ro’, label=’Original predictions’)
plt.plot(x_test, sine_model_predictions, ‘bx’, label=’Lite predictions’)
plt.plot(x_test, sine_model_quantized_predictions, ‘gx’, label=’Lite quantized predictions’)
plt.legend()
plt.show()
Clicchiamo su play della cella e verrà generato questo grafico:
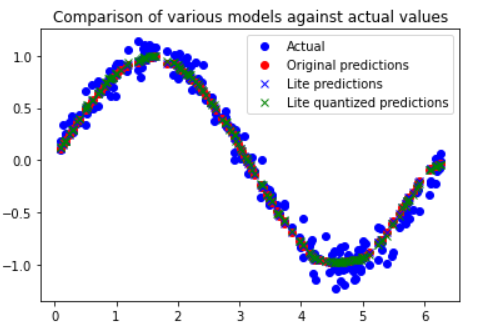
che mette a confronto i valori di riferimento del test (actual), i valori previsti dal modello originario (original prediction), i valori previsti dal modello trasformato per TF Lite (Lite prediction) ed i valori del modello quantizzato in TF Lite (Lite quantized prediction).
Come è possibile osservare i valori sono tutti abbastanza allineati tra loro senza scostamenti significativi.
Possiamo avere informazioni anche su quanto è stato ridimensionato il modello facendo un confronto fra modello in TF Lite e TF Lite quantizzato con il seguente codice da scrivere in una nuova cella:
import os
basic_model_size = os.path.getsize(“sine_model.tflite”)
print(“Basic model is %d bytes” % basic_model_size)
quantized_model_size = os.path.getsize(“sine_model_quantized.tflite”)
print(“Quantized model is %d bytes” % quantized_model_size)
difference = basic_model_size – quantized_model_size
print(“Difference is %d bytes” % difference)
Lanciamo ancora una volta il codice contenuto nella cella tramite il tasto play e si vedrà che la riduzione è di circa 900 bytes su 4300 bytes, cioè una riduzione di oltre il 20%.
A questo punto c’è ancora un passaggio da fare ed è quello di convertire il modello in linguaggio C per poter essere utilizzato con TensoFlow Lite per microcontrollori.
Per fare questo, ancora una volta, aggiungiamo una cella e scriviamo il seguente codice:
# Install xxd if it is not available
!apt-get -qq install xxd
# Save the file as a C source file
!xxd -i sine_model_quantized.tflite > sine_model_quantized.cc
# Print the source file
!cat sine_model_quantized.cc
Con l’esecuzione del codice viene generato un file con estensione “.cc”. Potete vedere tutti i file generati su Colab cliccando sulla “cartella” a sinistra del Notebook..

E con questo, abbiamo terminato di realizzare il nostro modello che è stato addestrato, valutato e convertito in deep learning per TensorFlow Lite che può prendere un numero compreso tra 0 e 2 π e riprodurre, con una soddisfacente approssimazione, il valore di sin (x).
Questo realizzato è solo una parte della procedura di impacchettamento, infatti per poter utilizzare il modello occorre creare una vera e propria applicazione.
Realizzazione dell’Applicazione (Sketch) che utilizza il Modello TinyML
L’obiettivo di questo paragrafo è quello di illustrare in modo del tutto generale la procedura per realizzare una applicazione che consenta il seguente processo:

cioè realizzare uno sketch per la nostra board Arduino Nano 33 BLE Sense che preso un valore numerico di input, opportunamente formattato, e dato in pasto al modello, ne tira fuori un output previsionale vicino al valore di sin(x).
Per fare questo analizziamo lo sketch di esempio presente nell’IDE Arduino, lanciamo l’applicazione e andiamo su:
File -> Esempi -> Arduino_TensorFlowLite -> hello_world

Viene caricato lo sketch:
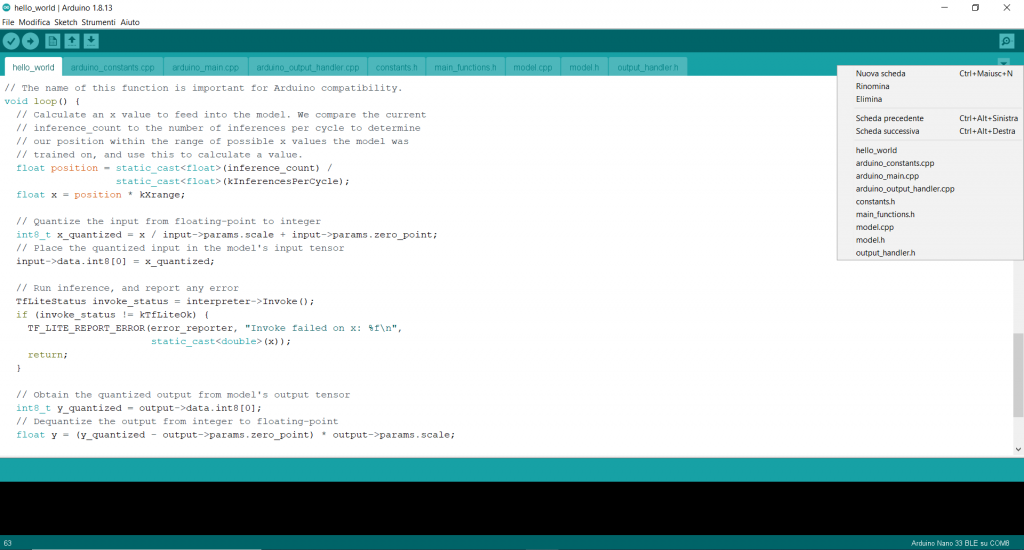
che è composto da 9 schede:
1. hello_world
2. arduino_constants.cpp
3. arduino_main.cpp
4. arduino_output_handler.cpp
5. costants.h
6. main_functions.h
7. model.cpp
8. model.h
9. output_handler.h
La prima scheda è il corpo principale dello sketch, infatti in questa scheda vengono richiamate tutte le librerie e le funzioni utilizzate dallo stesso sketch, c’è la funzione “void setup () { …. } “ e la funzione “void loop () { …. } “ . Nella funzione di setup, vengono effettuati tutti i controlli sulla versione dì TF Lite e la verifica di compatibilità con il modello, inoltre vengono inizializzate le funzione di TF Lite ed allocata la memoria dei tensori per il processo dell’inferenza.
Nella funzione di loop, vengono eseguite le operazioni principali richiamando le altre funzioni definite nelle altre schede, in particolare desidero far osservare la modalità di processo dell’inferenza nella previsione. Ovvero l’uso di variabili di tipo float per la definizione dell’input e per l’ottenimento del relativo output, sempre di tipo float e poi la fase di quantizzazione mediante la trasformazione da numeri di tipo float a numeri interi, dopo l’applicazione di opportune scale ai dati di input ed output.

Questo perché, come è stato scritto precedentemente, nel nostro caso l’input è un numero che va da 0 a 6,28… e l’output è un numero che va da 0 a +/- 1, per cui passare da un numero decimale (a virgola mobile) ad intero, si potrebbero perdere cifre significative e quindi falsare il risultato.
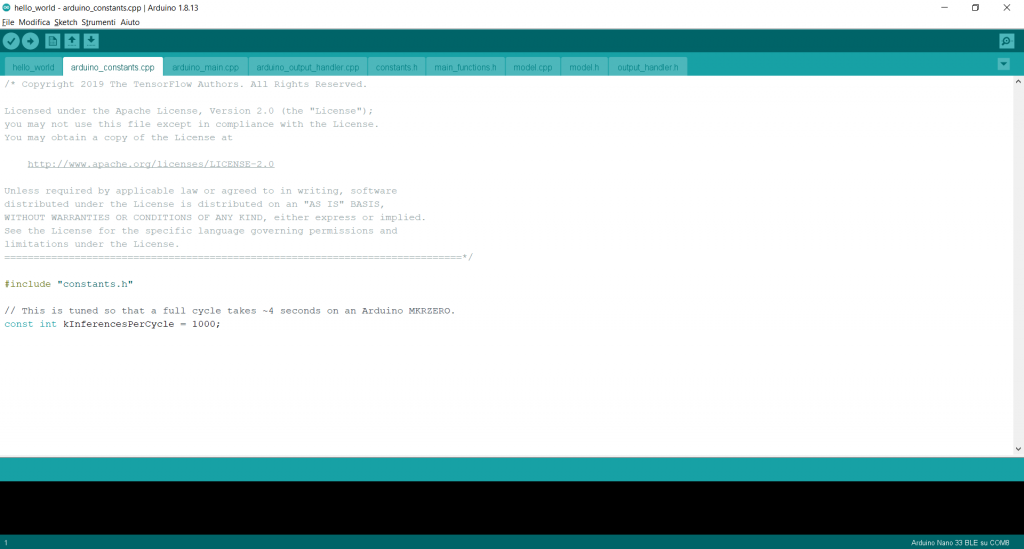
Nella seconda scheda “arduino_constants.cpp” viene definito il numero di inferenze. Esso è definito in base all’esperienza ed ai vari tentativi effettuati, per cui è un numero frutto dei risultati ottenuti.
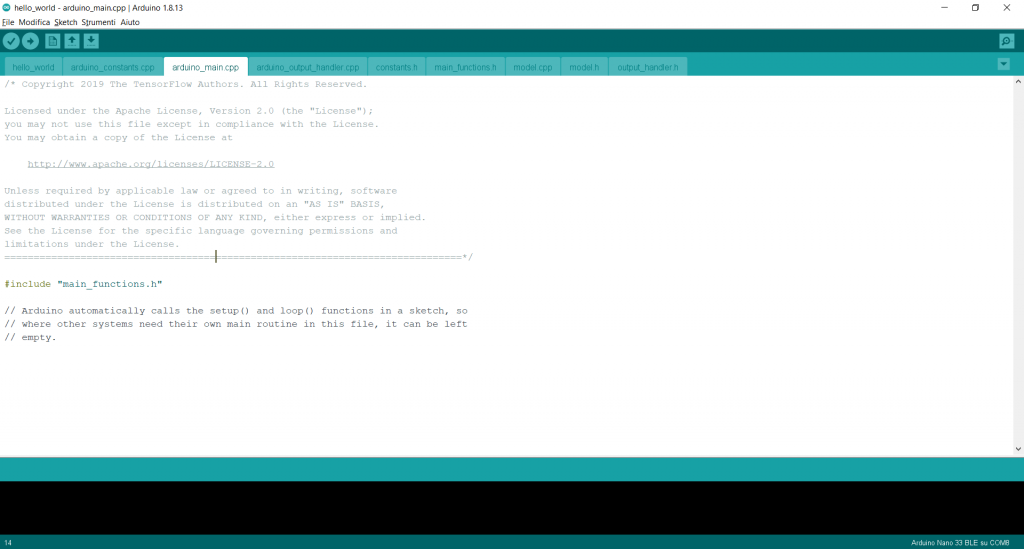
Nella terza scheda “arduino_main.cpp” vengono richiamate tutte le funzioni principali per l’IDE di Arduino.

Nella quarta scheda “arduino_output_handler.cpp” viene inserita la funzione che preso il valore di output dell’inferenza e quindi il valore previsto di sin(x) e viene trasformato in parametro PWM per stabilire la luminosità relativa del LED a bordo della scheda Arduino Nano.
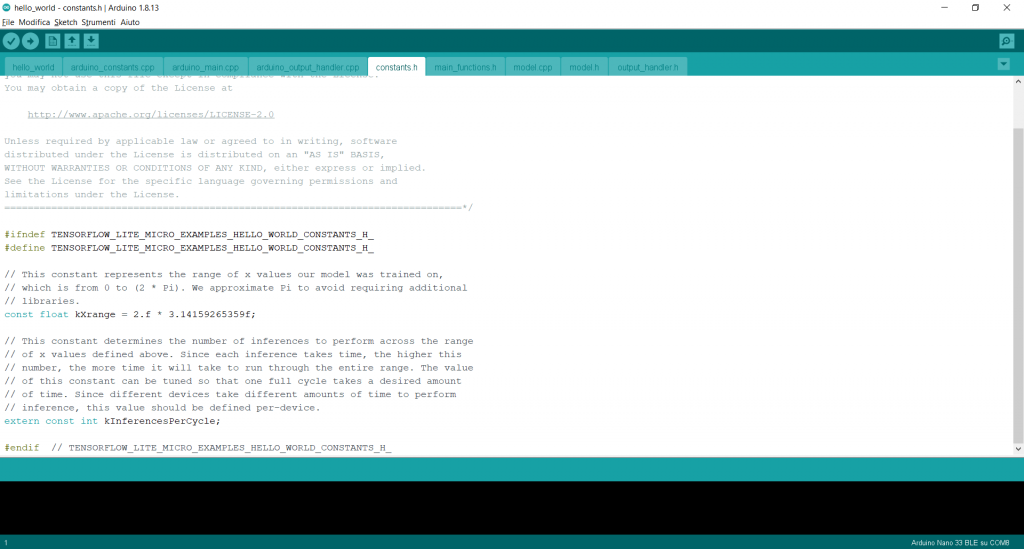
Nella quinta scheda “costants.h” viene definito il range di valori che può assumere l’input. Come si può osservare, il numero “pi greco” viene scritto in forma numerica troncandone il valore all’undicesima cifra decimale. Questo lo si fa perché altrimenti avremmo dovuto caricare un’altra libreria con impegno di ulteriore memoria.
La sesta scheda “main_functions.h” è quella che viene richiamata dalla terza scheda, per cui nulla di rilevante da evidenziare.
Nella settima ed ottava scheda, rispettivamente “model.cpp” e “model.h” , ci sono i file prodotti da TF Lite visti nel Capitolo iniziale e rappresentano il modello tradotto in linguaggio C.
Nella nona ed ultima scheda denominata “output_handler.h” sono richiamate le funzioni TF Lite per l’esecuzione delle inferenze e la definizione previsionale del valore di sin (x).
Conclusioni
Questo che ho voluto descrivere in questa lezione, e che completa il Corso Base sull’Intelligenza Artificiale applicata ai Microcontrollori, è una panoramica di ciò che occorre realizzare per passare dal modello costruito nelle lezioni precedenti e tradotto in linguaggio C, in un vero e proprio sketch utilizzabile dalla scheda Arduino Nano 33 BLE.
Mi rendo conto che questo passaggio non è ben dettagliato, come anch’io avrei voluto, ma se lo avessi fatto, avrei riempito paginate di teorie di calcolo numerico e descrizione di processi informatici che avrebbero sicuramente annoiato lo studente.
Infatti lo scopo di questo Corso e dare le basi dell’AI, in particolare del TinyML, applicata ad Arduino Nano 33 BLE Sense e generare quella sana curiosità che spinge lo studente stesso a proseguire con gli approfondimenti che ritiene utile fare.
A tal proposito suggerisco due libri ed il sito della TensorFlow che ho trovato molto utili e che ho utilizzato per ispirarmi a quanto riportato nelle pagine del Corso.
I link dei due libri e del sito sono:
- TinyML: Machine Learning With Tensorflow Lite on Arduino and Ultra-Low-Power Microcontrollers (di Pete Warden e Daniel Situnayake)
- TinyML Cookbook: Combine artificial intelligence and ultra-low-power embedded devices to make the world smarter (di Gian Marco Iodice)
- TensorFlow Lite
Al seguente link il video che mostra il funzionamento dello sketch Hello World ed anche alcune modifiche apportate per fare delle sperimentazioni.
Se hai trovato la lezione interessante fai una donazione mi aiuterai a realizzarne tante altre.
