TINY MACHINE LEARNING LEZIONE 7
INDICE
- Avvertenze
- Note sul Copyright
- Primo Step per la creazione del Modello Addestrato “Hello World”
- Il Dataset di addestramento
- PAI-015: I primi passi in Google Colab
- PAI-016: Realizzazione del Dataset “Hello World” su Colab
- PAI-017: Dati per Addestramento, Dati per la Validazione e Dati per i Test
- PAI-018: Completamento Dataset per Addestramento Modello

Avvertenze
Relativamente agli aspetti di sicurezza, poiché i progetti sono basati su alimentazione elettrica in bassissima tensione erogata dalla porta usb del pc o da batterie di supporto o alimentatori con al massimo 9V in uscita, non ci sono particolari rischi di natura elettrica. È comunque doveroso precisare che eventuali cortocircuiti causati in fase di esercitazione potrebbero produrre danni al pc, agli arredi ed in casi estremi anche a ustioni, per tale ragione ogni qual volta si assembla un circuito, o si fanno modifiche su di esso, occorrerà farlo in assenza di alimentazione e al termine dell’esercitazione occorrerà provvedere alla disalimentazione del circuito rimuovendo sia il cavo usb di collegamento al pc che eventuali batterie dai preposti vani o connettori di alimentazione esterna. Inoltre, sempre per ragioni di sicurezza, è fortemente consigliato eseguire i progetti su tappeti isolanti e resistenti al calore acquistabili in un qualsiasi negozio di elettronica o anche sui siti web specializzati.
Al termine delle esercitazioni è opportuno lavarsi le mani, in quanto i componenti elettronici potrebbero avere residui di lavorazione che potrebbero arrecare danno se ingeriti o se a contatto con occhi, bocca, pelle, etc. Sebbene i singoli progetti siano stati testati e sicuri, chi decide di seguire quanto riportato nel presente documento, si assume la piena responsabilità di quanto potrebbe accadere nell’esecuzione delle esercitazioni previste nello stesso. Per i ragazzi più giovani e/o alle prime esperienze nel campo dell’Elettronica, si consiglia di eseguire le esercitazioni con l’aiuto ed in presenza di un adulto.
Note sul Copyright
Tutti i marchi riportati appartengono ai legittimi proprietari; marchi di terzi, nomi di prodotti, nomi commerciali, nomi corporativi e società citati possono essere marchi di proprietà dei rispettivi titolari o marchi registrati d’altre società e sono stati utilizzati a puro scopo esplicativo ed a beneficio del possessore, senza alcun fine di violazione dei diritti di Copyright vigenti. Quanto riportato in questo documento è di proprietà di Roberto Francavilla, ad esso sono applicabili le leggi italiane ed europee in materia di diritto d’autore – eventuali testi prelevati da altre fonti sono anch’essi protetti dai Diritti di Autore e di proprietà dei rispettivi Proprietari. Tutte le informazioni ed i contenuti (testi, grafica ed immagini, etc.) riportate sono, al meglio della mia conoscenza, di pubblico dominio. Se, involontariamente, è stato pubblicato materiale soggetto a copyright o in violazione alla legge si prega di comunicarlo tramite email a info@bemaker.org e provvederò tempestivamente a rimuoverlo.
Roberto Francavilla
Primo Step per la creazione del Modello Addestrato “Hello World”

Nella Lezione 6 abbiamo visto cosa è la funzione sen(x) o anche scritta in inglese sin (x), quindi ignorando che esiste una funzione matematica che ci consente di disegnare la funzione seno in modo preciso, proviamo a farla costruire al nostro microcontrollore grazie al TinyML.
Possiamo anche utilizzare questa funzione come segnale PWM per far accendere in modo graduale ed alternato due LED di colore Verde e Rosso per indicarci quando si è nella fase di semionda positiva (verde) e quando si è nella fase di semionda negativa (rosso).
Ma adesso concentriamoci nel realizzare il nostro modello di Machine learning.
Sempre nella Lezione 6 abbiamo visto che un modello di Machine Learning si realizza per Fasi, la prima Fase che desidero affrontare è quella che riguarda la costruzione di un Dataset.
Il Dataset di addestramento

Il Dataset è un insieme di dati che viene utilizzato per fare l’addestramento iniziale del Modello.
Ovviamente il Dataset è stabilito in funzione di ciò che noi desideriamo che il nostro modello impari a prevedere, ad esempio, se vogliamo un modello che sia addestrato per fare previsioni meteo, il Dataset corrispondente dovrà contenere tutti quei valori di pressione, temperatura, e umidità (grandezze, magari, rilevate giornalmente nell’arco di diversi anni e nelle diverse stagioni) con il conseguente comportamento meteo. In questo modo il modello potrà imparare a fare previsioni meteo.
Ora, ritornando al nostro modello di ML da realizzare di Hello World e come ho scritto nella Lezione 6, questo set di dati viene costruito a tavolino dal programmatore del Machine Learning.
Per cui mettiamoci all’opera e per fare questo ho bisogno di spiegarvi uno strumento utilissimo che ci aiuta tantissimo nella realizzazione del nostro Dataset.
Questo strumento si chiama Jupyter Notebooks e nel cloud è offerto gratuitamente da Google Colab. Per usufruirne bisogna avere un account su Google, che vi suggerisco, infatti grazie anche a Drive di Google possiamo anche memorizzare nel cloud i nostri progetti ed anche condividerli.
Colab è un ambiente di sviluppo particolarmente pratico e facile da utilizzare, inoltre ci consente di avere visibilità, mediante rappresentazioni grafiche, anche dello stato del nostro Dataset.
Il linguaggio di programmazione utilizzato in Colab è il Python, ma non vi preoccupate, è tutto facile, vi guiderò passo passo in tutto.
PAI-015: I primi passi in Google Colab
Non è mia intenzione fare un corso su Colab, per cui non preoccupatevi, il mio obiettivo è darvi gli strumenti iniziali per poter utilizzare Colab da subito e velocemente, ovviamente Colab è uno strumento potentissimo e molto interessante e vi sono tantissimi tutorial che ne spiegano il funzionamento e l’utilizzo, per cui lascio a questi tutorial eventuali vostri approfondimenti, io personalmente ho intenzione solo di spiegarvi passo passo come costruire il nostro Dataset e con l’occasione spiegarvi anche come utilizzare Colab al meglio ed in modo elementare.
Per iniziare, una volta creato il vostro account Google, accedete a Colab cliccando sul link accanto link
Vi compare la finestra di benvenuto:
Cliccate su File (in alto a sinistra) e poi su Nuovo blocco note
A questo punto avrete a disposizione una pagina di blocco note dove potrete inserire del codice o delle parti di testo, ma anche foto, video, etc…a noi non interessa… utilizzeremo Colab solo per testare il nostro Dataset iniziale:
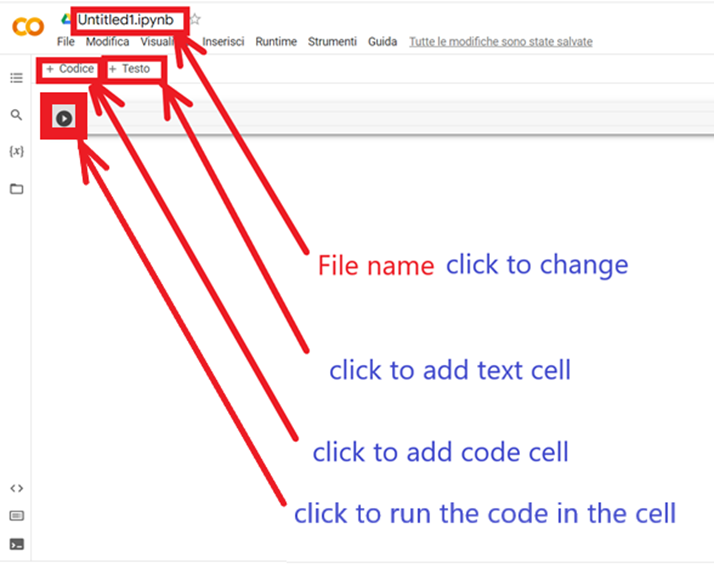
Il blocco note è organizzato in celle, le celle che contengono il codice di programma posso essere anche eseguite cliccando sulla freccina “play” in alto a sinistra alla cella. Una volta eseguito la parte di codice, viene messo il segno di spunta.
Facciamo un esempio pratico: Carichiamo le librerie matematiche e di grafica e facciamo disegnare la funzione seno. Per fare questo, scriviamo all’interno della cella di codice:
import numpy as np
import math
import matplotlib.pyplot as plt
Con le istruzioni sopra stiamo dicendo al compilatore Colab di caricare tre librerie, due di matematica ed una di grafica per plottare i risultati. Come è possibile osservare dal codice, con l’istruzione “import” carichiamo la libreria, poi c’è l’istruzione “as”, in questo caso l’istruzione dice al compilatore che da questo momento in poi (ad esempio) la libreria “numpy” si chiamerà “np”, quindi in sostanza l’istruzione “as” ci aiuta ad assegnare nomi più facili da memorizzare e più semplici da scrivere, per quella determinata libreria. Ovviamente, i nomi “np” e “plt” sono arbitrari.
Poi clicchiamo su aggiungi cella codice e nella cella scriviamo:
x_values = np.linspace(0, 2 * math.pi, 1000)
y_values = np.sin(x_values)
plt.plot(x_values, y_values, ‘r’)
Nella prima riga stiamo costruendo un array (cioè un vettore) da 1000 elementi con valori che vanno da 0 a 2 π considerando che π = 3,14, allora 2 π = 6,28 .
Questo è un valore espresso in radianti e rappresenta l’angolo giro, ovvero 360°.
Nella seconda riga creiamo un array (un altro vettore) di dimensione uguale a x_values, ma gli elementi sono il calcolo del seno del corrispondente valore dell’angolo in radianti. In sostanza abbiamo costruito un array con il valore del seno rispetto all’angolo espresso in radianti che va da 0 a 360°.
Nella terza riga, facciamo “plottare” i dati di input (angolo in radianti) e di output (valori del seno) con una linea di colore rosso “r” e si ottiene così (clicchiamo sul play delle due celle):

…una meravigliosa onda sinusoidale….
PAI-016: Realizzazione del Dataset “Hello World” su Colab
Cliccate su File (in alto a sinistra) e poi su Nuovo blocco note
…e nella prima cella di Colab ricopiamo il codice sotto:
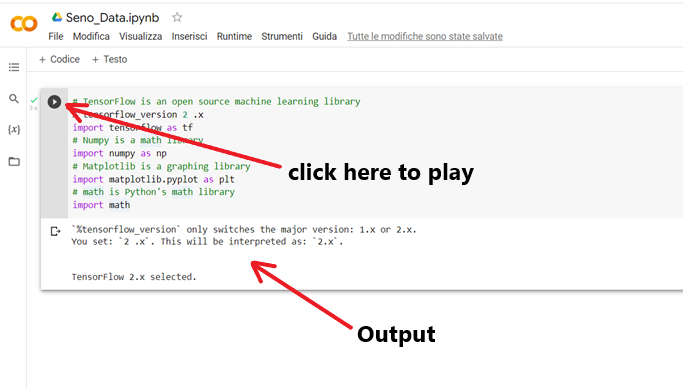
# TensorFlow is an open source machine learning library
% tensorflow_version 2 .x
import tensorflow as tf
# Numpy is a math library
import numpy as np
# Matplotlib is a graphing library
import matplotlib.pyplot as plt
# math is Python’s math library
import math

La riga con “#” è una riga di commento.
La riga” import tensorflow as tf” istalla la libreria TensorFlow. La libreria “tensorflow” caricata viene ridenominata tramite la sigla “tf”.
Le righe successive sono identiche al progetto precedente, vengono richiamate le librerie “numpy”, “matplotlib.pyplot” e “math” e ridenominate “np” e “plt”, mentre math, resta con il proprio nome. Ricordo che sono librerie matematiche e per il plottaggio dei risultati.
A questo punto lanciamo l’esecuzione del codice contenuto nella cella cliccando sul play
Poiché il nostro scopo è quello di addestrare un modello con il fine che assegnato un input (che è un angolo espresso in radianti), la previsione del modello sia il calcolo del seno dell’angolo dato come input, allora è ovvio che il nostro Dataset sarà costruito sulla base di valori di seno già noti. Avendo studiato precedentemente la funzione seno, sappiamo che il seno è una funzione periodica e si ripete dopo ogni “periodo” indicato dall’angolo giro, cioè i 360°.
Per cui la funzione seno avrà un valore che parte da 0, raggiunge 1, poi ritorna a zero e va a -1, infine ritorna a zero, con l’angolo che andrà da 0 a 2 , dopodiché i valori della funzione e dell’angolo, si ripetono.
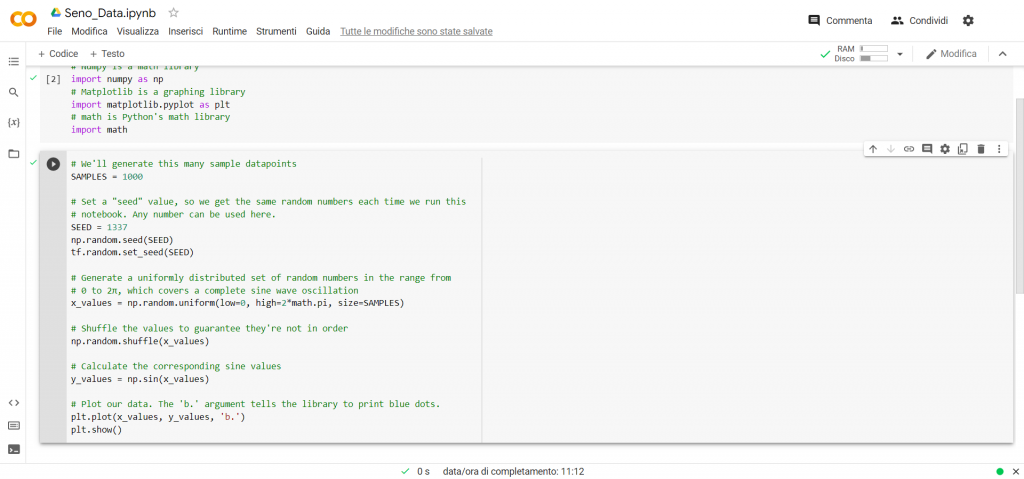
Per costruire questo Dataset aggiungiamo un’altra cella in Colab e scriviamo le seguenti righe di programma:
# We’ll generate this many sample datapoints
SAMPLES = 1000
# Set a “seed” value, so we get the same random numbers each time we run this
# notebook. Any number can be used here.
SEED = 1337
np.random.seed(SEED)
tf.random.set_seed(SEED)
# Generate a uniformly distributed set of random numbers in the range from
# 0 to 2π, which covers a complete sine wave oscillation
x_values = np.random.uniform(low=0, high=2*math.pi, size=SAMPLES)
# Shuffle the values to guarantee they’re not in order
np.random.shuffle(x_values)
# Calculate the corresponding sine values
y_values = np.sin(x_values)
# Plot our data. The ‘b.’ argument tells the library to print blue dots.
plt.plot(x_values, y_values, ‘b.’)
plt.show()
Vediamo riga per riga cosa abbiamo scritto….
SAMPLES = 1000
Con la variabile “SAMPLES” indichiamo il numero di valori (campioni) che vogliamo memorizzare nell’array dei dati di input e di output. In questo caso decidiamo di memorizzare 1000 campioni.
SEED = 1337
Con la variabile “SEED” fissiamo “il seme” per la generazione di numeri casuali. E’ utile fissare il seme in modo tale da avere sempre la generazione degli stessi numeri casuali ogni volta che si lancia il notebook di Colab. Il valore 1337 è un numero arbitrario (lascio il valore 1337 perché è quello riportato nell’esempio pubblico di Hello World che potete trovare su GitHub)
np.random.seed(SEED)
Con la funzione “np.random.seed (SEED)” viene inizializzato il generatore di numeri casuali con un valore di seme di riferimento (se non si dovesse specificare alcun seme, il seme utilizzato è l’ora del sistema).
tf.random.set_seed(SEED)
Con la funzione “tf.random.set_seed(SEED)” viene inizializzato il generatore di numeri casuali per l’ambiente TensorFlow, questo è un generatore globale di numeri casuali. Anche per questo occorre un valore di seme di riferimento.
x_values = np.random.uniform(low=0, high=2*math.pi, size=SAMPLES)
Una volta inizializzato il generatore di numeri, con la funzione “np.random.uniform(low=0, high=2*math.pi, size=SAMPLES)” glieli facciamo definire e li inseriamo in un array da 1000 elementi. Per questa funzione desidero far notare che viene dato un range per i numeri casuali da produrre, cioè quelli che vanno da 0 a 2 . Una volta generato il numero casuale, viene inserito nella variabile array denominata “x_values”.
np.random.shuffle(x_values)
La funzione “np.random.shuffle(x_values)” è utilizzata per mescolare casualmente gli elementi di un array. A tal proposito, occorre evidenziare che il processo di addestramento utilizzato nel deep learning dipende dai dati che gli vengono inviati e se questi sono in un ordine veramente casuale il modello risultante è più accurato rispetto al caso di invio di dati in modo ordinato.
y_values = np.sin(x_values)
La funzione “np.sin(x_values)” definisce un array i cui elementi sono il valore del seno del angolo corrispondente all’array “x_values”.
plt.plot(x_values, y_values, ‘b.’)
plt.show()
Con le istruzioni sopra viene plottato il grafico rappresentativo dei valori contenuti nei due array x_values e y_values. L’argomento “b.”, indica il colore da utilizzare per la stampa del grafico, in particolare di colore blu.
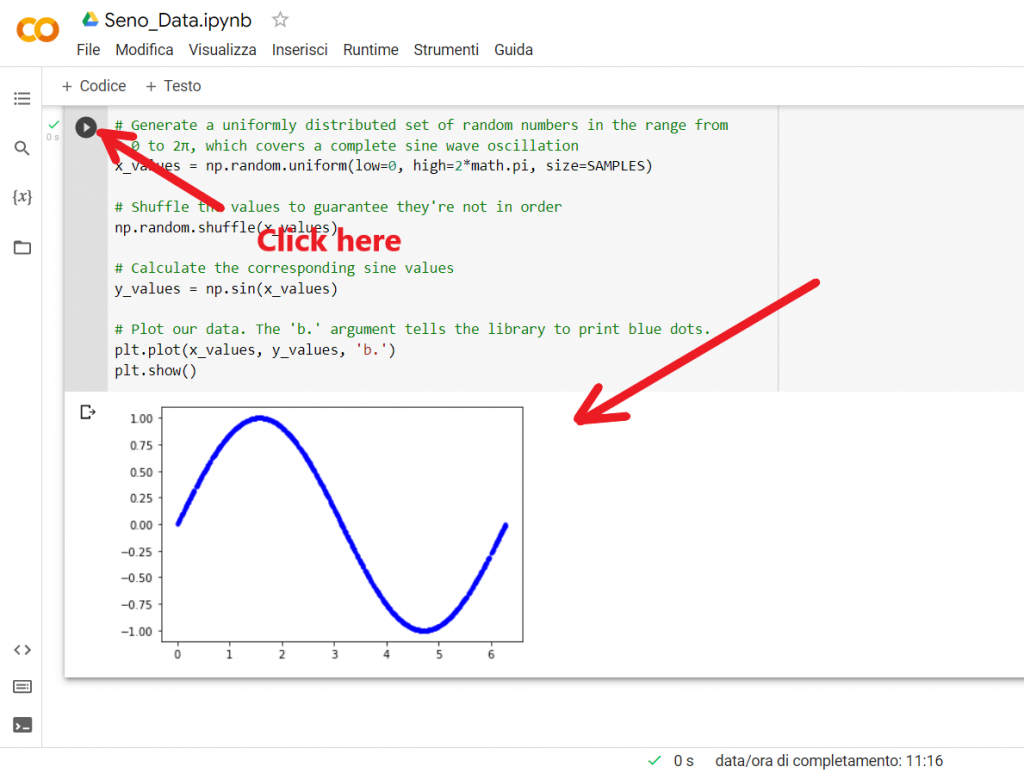
A questo punto abbiamo costruito il nostro Dataset di addestramento, ma per dare anche un senso di casualità dei dati creati e simulare quindi un insieme di dati pseudo-raccolti (questa prassi migliora l’efficienza di addestramento del modello!), introduciamo ulteriori dati casuali fuori valore del seno. In gergo viene detto che si introduce del rumore di fondo ai dati.
Per fare questo, ai nostri elementi che sono all’interno dell’array con i valori calcolati del seno, gli aggiungiamo un piccolo valore casuale (il valore aggiunto casualmente può anche essere negativo, per cui in realtà c’è una detrazione nel valore).
In termini di codice quindi, aggiungiamo una ulteriore cella e sciviamo il seguente programma:
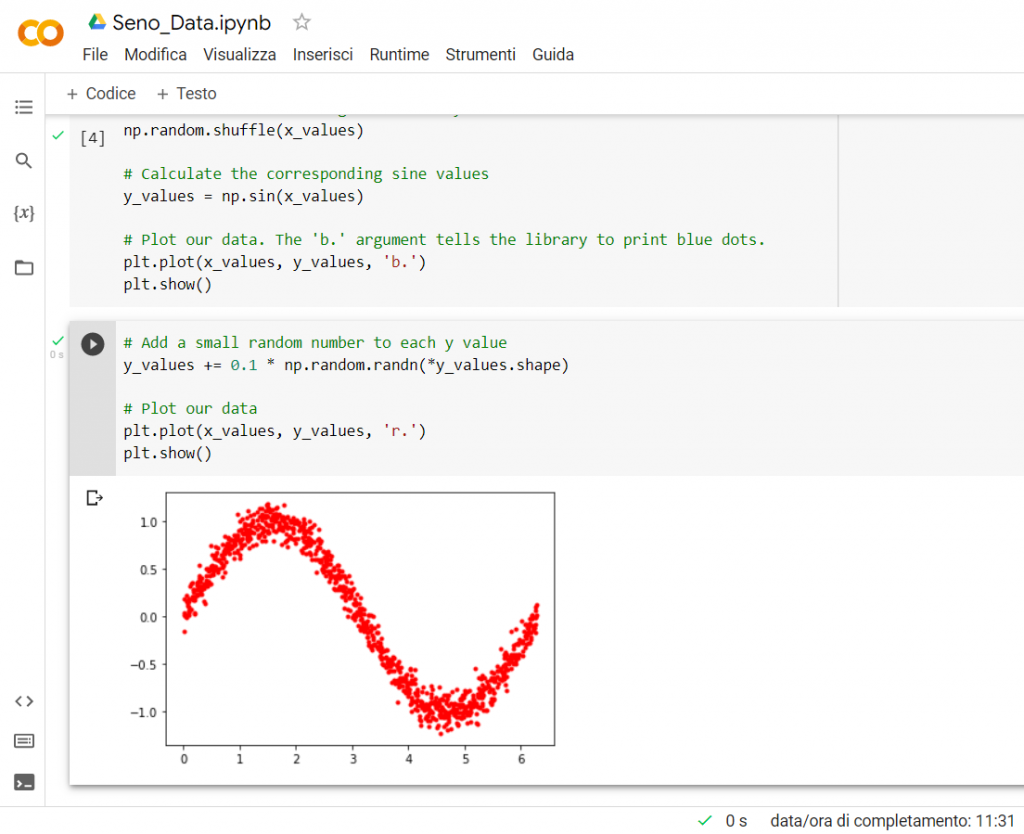
# Add a small random number to each y value
y_values += 0.1 * np.random.randn(*y_values.shape)
# Plot our data
plt.plot(x_values, y_values, ‘r.’)
plt.show()
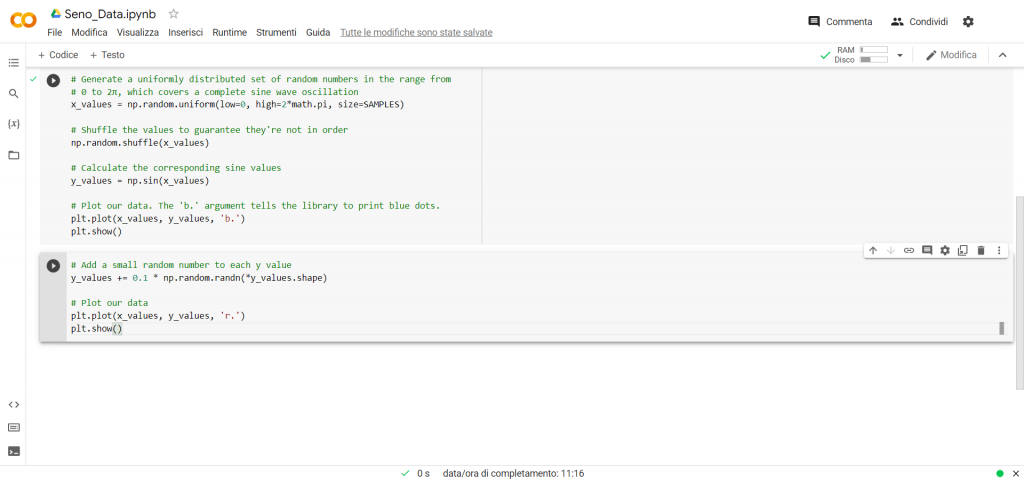
Analizziamo la funzione “y_values += 0.1 * np.random.randn(*y_values.shape)”. I valori contenuti nell’array “y_values” sono valori della funzione seno ed essi vanno da – 1 a +1, allora se prendo questi valori e li uso come seme per determinare dei valori casuali, otterrò ancora una generazione di valori casuali compresi tra -1 e +1. Infatti questo l’ottengo con la funzione “np.random.randn(*y_values.shape)”. Poi moltiplico questo valore casuale per 0,1 (cioè ne calcolo il 10%) e il valore ottenuto lo vado a sommare al corrispondente valore dell’elemento dell’array y_values.
In sostanza abbiamo in questo modo costruito una distribuzione di numeri casuali (rispetto al valore di seno) che conservano una distribuzione a forma di seno, ma i cui valori non sono quelli del seno e il range di variazione di tali valori casuali è del +/-10% intorno al valore del seno.
Dopodiché facciamo riplottare i valori, questa volta di colore rosso.
PAI-017: Dati per Addestramento, Dati per la Validazione e Dati per i Test
A questo punto occorre introdurre un ulteriore concetto importante per il completamento del nostro Dataset ed è quello che affinché il modello ML possa essere addestrato adeguatamente è necessario introdurre nel set di dati di addestramento anche dei dati di validazione e dei dati per i test. Per cui un Dataset è un insieme di dati che si suddividono in Dati per l’Addestramento, Dati per la Validazione e Dati per i Test.
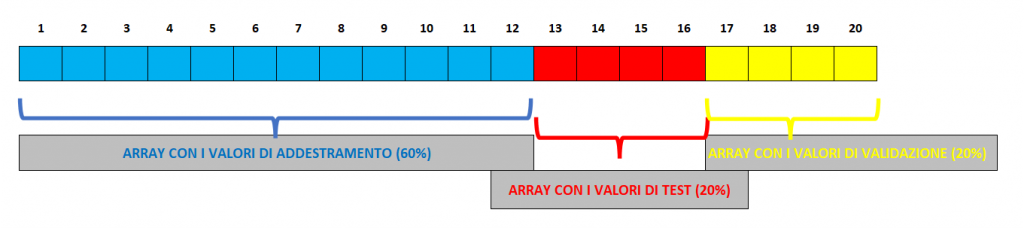
In genere il peso che si da per queste tre tipologie di Dati è :
- 60% dati per l’Addestramento
- 20% dati per la Validazione
- 20% dati per i Test
Per vedere come si ottiene da un insieme di dati una suddivisione degli stessi secondo le nostre necessità, facciamo prima un esempio elementare ed utilizzeremo una funzione Python, in particolare della Libreria “numpy”, chiamata “.split”.
Facciamo un esempio pratico.
Cliccate su File (in alto a sinistra) e poi su Nuovo blocco note e scriviamo il seguente codice:
import numpy as np
Campioni = 20
Seme = 1337
np.random.seed(Seme)
x_values = np.random.uniform(low=0, high=6.28, size=Campioni)
print(“Array X=”, x_values)
y_values = np.sin(x_values)
print(“Array Y=”, y_values)
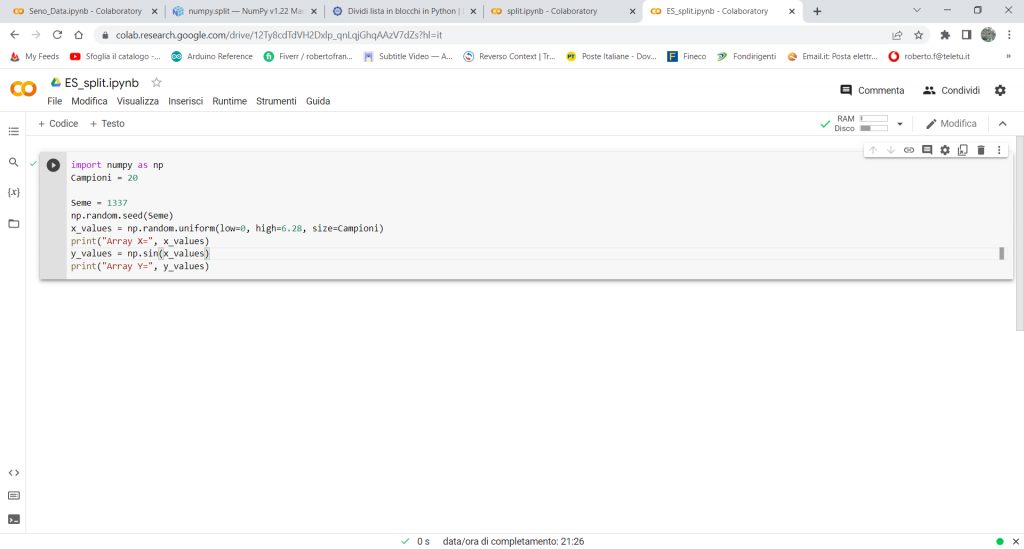
Con il codice sopra, senza entrare nel dettaglio di istruzioni e funzioni già viste, abbiamo creato un array con 20 valori casuali compresi tra 0 e 6,28. Poi costruiamo un array formato da 20 elementi, dove ogni elemento corrisponde al valore del seno del corrispondente valore dell’elemento dell’array x_values.
Aggiungiamo un’altra cella e scriviamo il seguente codice:
Dati_Addestramento = int(0.6 * Campioni)
Dati_Test = int(0.2 * Campioni + Dati_Addestramento)
x_train, x_test, x_val = np.split(x_values, [Dati_Addestramento, Dati_Test])
y_train, y_test, y_val = np.split(y_values, [Dati_Addestramento, Dati_Test])
assert (x_train.size + x_val.size + x_test.size) == Campioni
print(“Array X_T=”, x_train)
print(“Array Y_T=”, y_train)
print(“Array X_TS=”, x_test)
print(“Array Y_TS=”, y_test)
print(“Array X_V=”, x_val)
print(“Array Y_V=”, y_val)
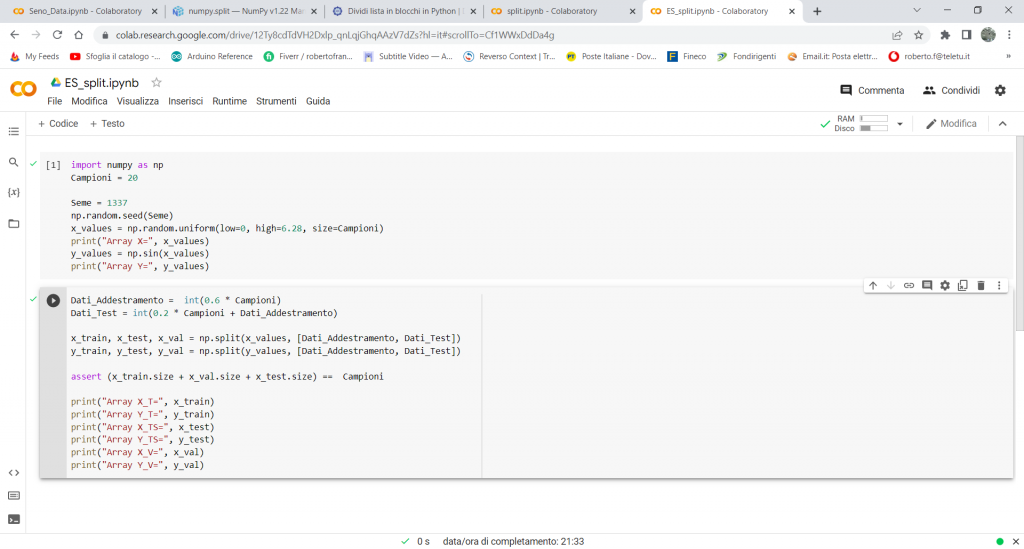
In questa seconda cella invece vediamo in dettaglio cosa stiamo facendo.
Con il calcolo “Dati_Addestramento = int(0.6 * Campioni)” stiamo definendo una variabile intera con il valore del 60% del numero di Campioni, per cui se i Campioni sono 20, la variabile assumerà il valore di 12.
Con il calcolo” Dati_Test = int(0.2 * Campioni + Dati_Addestramento)” stiamo assegnando alla variabile intera Dati_Test un valore che è pari alla somma del valore della variabile precedentemente calcolata (cioè di Dati_Addestramento”) con il 20% del numero di Campioni totali. Per cui il valore precedente era di 12, a cui andrà sommato il 20% di 20, cioè 4, per un totale di 16.
Questi due valori ci sono utili nella divisione dell’array con la funzione .split Infatti, con la funzione “x_train, x_test, x_val = np.split(x_values, [Dati_Addestramento, Dati_Test])” noi stiamo dividendo l’array in tre parti, dall’elemento 1 all’elemento 12, ci sono i valori di addestramento, dal 13 al 16 quelli di Test e dal 17 al 20quelli di validazione:
Infatti lanciamo l’esecuzione delle due celle ed otteniamo:

A questo punto possiamo completare il nostro Dataset per l’addestramento del Modello.
PAI-018: Completamento Dataset per Addestramento Modello
Apriamo il Notebook di Colab precedentemente realizzato denominato Seno_Data ed aggiungiamo una cella di codice e ci scrviamo il seguente codice:
# We’ll use 60% of our data for training and 20% for testing. The remaining 20%
# will be used for validation. Calculate the indices of each section.
TRAIN_SPLIT = int(0.6 * SAMPLES)
TEST_SPLIT = int(0.2 * SAMPLES + TRAIN_SPLIT)
# Use np.split to chop our data into three parts.
# The second argument to np.split is an array of indices where the data will be
# split. We provide two indices, so the data will be divided into three chunks.
x_train, x_test, x_validate = np.split(x_values, [TRAIN_SPLIT, TEST_SPLIT])
y_train, y_test, y_validate = np.split(y_values, [TRAIN_SPLIT, TEST_SPLIT])
# Double check that our splits add up correctly
assert (x_train.size + x_test.size + x_validate.size) == SAMPLES
# Plot the data in each partition in different colors:
plt.plot(x_train, y_train, ‘b.’, label=”Train”)
plt.plot(x_test, y_test, ‘r.’, label=”Test”)
plt.plot(x_validate, y_validate, ‘y.’, label=”Validate”)
plt.legend()
plt.show()

Cliccando sul “play” della cella viene mostrata la distribuzione dei dati realizzata:
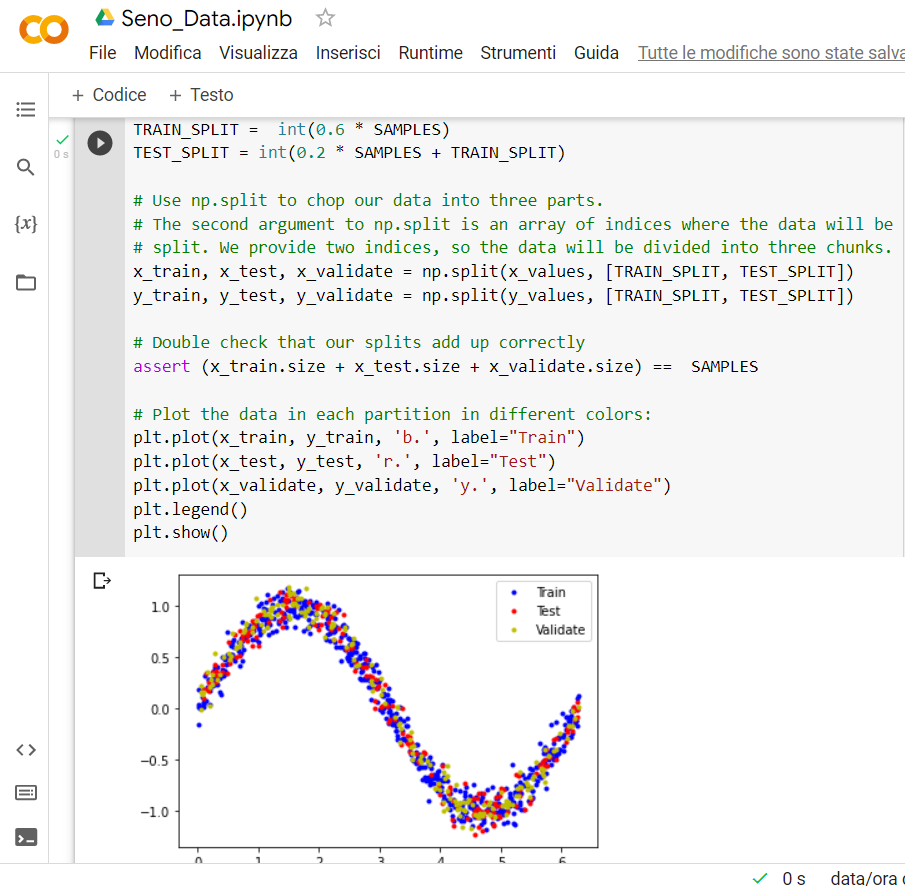
Con questo termina il Dataset per l’apprendimento del nostro modello.
Se hai trovato la lezione interessante fai una donazione mi aiuterai a realizzarne tante altre.
